

Prometheus教程(3)PromQL用法详解
一、PromQL 基本介绍
PromQL 全称 Prometheus Query Language,它是 Prometheus 专用查询语言。通过PromQL可以灵活的对每个指标实现条件查询、算术运算、比较操作符、正则表达式、聚合操作符、逻辑操作符等操作。Grafana图形配置时也是基于PromQL实现,所以要使用Prometheus的话PromQL是重中之重,在PromQL中有以下核心概念:
· 指标(Metric):Prometheus 中所有数据都以指标的形式存在,每条指标由一个名字和多个标签组成
· 标签(Label):通过标签可以对一个时间序列的不同维度进行展示
· 时间序列(Time Series):不同标签所组合而形成的唯一数据就是一个时间序列,即便指标相同但是标签不同,那么对于Prometheus来说也是不同的时间序列
· 瞬时向量(Instant Vector):某一时刻多个时间序列的当前值
· 区间向量(Range Vector):某一时刻向前回溯一段时间后的多个时间序列的集合
· 标量(Scalar):一个单一的数值,常用于计算或比较结果
二、PromQL 查询语法
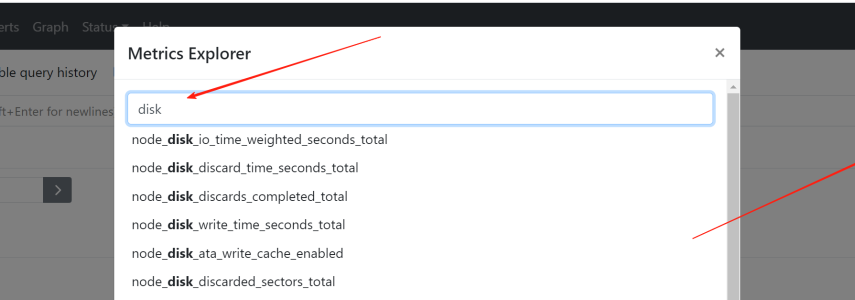
在Prometheus的查询窗口输入PromQL就可以进行数据查询,每个exporter都提供了大量的指标(点击执行按钮旁的地球仪符号可以看到所有指标),直接使用指标名称就可以执行查询操作。查询出来的数据可以进行算术运算、比较操作等操作

1、查询指标当前值
比如通过node_filesystem_avail_bytes这个指标查询文件系统可用空间,然后将默认的bytes换算为GB单位
node_filesystem_avail_bytes/1024/1024/1024
查询效果如下

2、带标签的过滤查询
标签是 PromQL 的核心,通过标签可以决定数据的粒度和分组维度。相同的 metric 名称,但不同的 label 组合,代表的是完全不同的时间序列。通过标签匹配可以实现更细化的监控需求,比如只查询符合xx条件的xx主机,标签支持精确匹配、正则匹配等
#PromQL标签语法
#指标名后面的花括号{}中声明标签的键值对
metric_name{label_name="label_value"}
# 精确匹配
node_cpu_seconds_total{mode="user"}
# 多标签匹配
http_requests_total{environment="production",method="GET"}
# 非等于(排除)
http_requests_total{environment!="development"}
# 正则表达式匹配,可实现匹配多个值
node_cpu_seconds_total{mode=~"user|system"}
# 正则不匹配
node_filesystem_avail_bytes{mountpoint!~"/boot|/tmp"}3、PromQL的比较运算符
PromQL运算符用于过滤满足条件的时间序列,在实际监控和告警规则中非常常见,支持的运算符有=、>、<、!=、>=、<=。比较运算符通常是对瞬时向量与一个标量进行比较,默认只显示符合条件(判断结果为真)的时间序列,不满足条件的时间序列会被过滤掉,不出现在结果中。如果想要明确地看到哪些时间序列满足条件、哪些不满足,可以使用bool修饰符将所有的时间序列都显示在结果中,满足条件的序列会有一个值为1(true),不满足的序列会有一个值为0(false)。
#判断node_exporter job中哪些实例不存活
up{job="nodex_exporter"} ==0
#判断内存超过70%的实例
{node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes} / node_memory_MemTotal_bytes * 100 > 70如果要对不同的向量进行比较,向量之间必须具有相同的标签。例如,下面两个时间序列可以成功进行一对一匹配,因为它们的标签以及标签值完全一致才能进行比较运算
http_requests_total{job="webserver", instance="192.168.1.100:9100"}
http_requests_duration_seconds{job="webserver", instance="192.168.1.100:9100"}如果向量之间的标签无法对齐而又存在比较需求,此时就需要on / ingore 关键词来声明需要比较或者需要忽略的标签。
用法含义说明
· on():只用列出的标签进行对齐
· ignoring():忽略列出的标签进行对齐
#只根据 instance 匹配,忽略其他标签 rate(http_errors_total[5m]) / on(instance) rate(http_requests_total[5m]) #忽略 job、method 等标签,仅按 instance 匹配 rate(metric1[5m]) > ignoring(job, method) rate(metric2[5m])
使用on或ingore语句的时候还可以使用 group_left 和 group_right 修饰符指定进行多对一或一对多的匹配关系,在进行一对多或多对一匹配时,先用on或ingore语句来去掉多余的标签,然后哪边的标签多就group哪边,通常 group_left 使用更加频繁,因为在 PromQL 中我们习惯把更详细的指标放在表达式左边,二者区别如下:
· group_left:多对一匹配,保留左侧向量的所有标签,使用一个右侧样本与左侧的多个样本进行匹配
· group_right:一对多匹配,保留右侧向量的所有标签,使用一个左侧样本与右侧的多个样本进行匹配

# 使用 on 指定要匹配的标签
# http_requests_total{environment="prod"} / on(instance) cpu_usage{environment="prod"}
# 使用 on 匹配 job 和 instance 标签
process_cpu_seconds_total / on(job, instance) process_resident_memory_bytes
# 使用 ignore 忽略 environment 标签进行匹配
http_requests_total / ignoring(environment) cpu_usage
# 忽略多个标签进行匹配
sum(http_requests_total) / ignoring(job, environment) sum(cpu_usage)
# 实际应用,计算每个实例的 HTTP 请求错误率
sum by (instance) (rate(http_requests_total{status=~"5.."}[5m])) / on(instance) sum by (instance) (rate(http_requests_total[5m]))
# 计算每个服务的内存使用率(已用/总量)
process_resident_memory_bytes / on(instance, job)
group_left process_memory_limit_bytes * 100
sum(node_cpu_seconds_total) by (instance,job,mode) / ignoring(mode)
group_left sum(node_cpu_seconds_total)by(instance,job)
# group_left 示例(多对一匹配)
# 1、假设有以下指标:
# node_cpu_seconds_total{cpu="0", mode="idle", instance="host1"} 1234
# node_cpu_seconds_total{cpu="1", mode="idle", instance="host1"} 5678
# node_memory_total_bytes{instance="host1"} 8589934592
# 2、计算每个 CPU 核心的内存使用率
node_cpu_seconds_total / on(instance) group_left node_memory_total_bytes
# 3、结果会保留 cpu 和 mode 标签
# {cpu="0", mode="idle", instance="host1"} 1234/8589934592
# {cpu="1", mode="idle", instance="host1"} 5678/8589934592
# group_right 示例(一对多匹配)
# 1、假设有以下指标:
# http_requests_total{instance="host1"} 1000
# node_cpu_seconds_total{cpu="0", mode="idle", instance="host1"} 1234
# node_cpu_seconds_total{cpu="1", mode="idle", instance="host1"} 5678
# 2、计算每个 CPU 核心处理的请求数
http_requests_total / on(instance) group_right(cpu,mode) node_cpu_seconds_total
# 3、结果会保留右侧向量的 cpu 和 mode 标签:
# {cpu="0", mode="idle", instance="host1"} 1000/1234
# {cpu="1", mode="idle", instance="host1"} 1000/56784、时间范围查询
在 PromQL 中,通过区间向量表示某条时间序列在当前查询时刻之前的一段时间内的所有采样值。其语法很简单,只需要在指标后使用方括号[ ]并指明一个时间范围就可以查询出该时间区间内的数据,时间范围的单位支持s,m,h,比如查询符合xx条件的xx主机最近5分钟的数据
#语法
metric_name[时间范围]
http_requests_total{environment="production"}[5m]使用offset关键词可以进行时间偏移量查询,主要用于对比不同时间点的数据,例如今天QPS是10000,昨天这个时间是5000,然后计算增长率
# 1小时前的数据 http_requests_total offset 1h # 计算同比增长率 (http_requests_total - http_requests_total offset 1d) / http_requests_total offset 1d # 查询一周前基于某个时间范围的数据,比如从当前时间往回推一周,持续5分钟的数据范围内的node load1指标 node load1 [5m] offset 1w
同环比对比分析示例:
对比“当前时间点接收的网络流量”与"1小时前的流量”,以判断流量是增长还是减少。而计算同环比的增长率或减少率的公式:同环比率=当前流量-过去1小时的流量/过去1小时的流量 x 100。例如,当前总接收流量是6000MB,1小时前接收的总流量是5000MB,那么计算公式为:(6000-5000)/5000*100=20%(意味着相比1小时前,当前流量增长了20%)
(node_network_receive_bytes_total - node_network_receive_bytes_total offset 1h) / node_network_receive_bytes_total offset 1h * 100
5、PromQL的分组与聚合
同一个指标(如 http_requests_total)可以因为不同标签产生有多条时间序列。通过分组的方式可以按照指定的标签对这些时间序列分组,并对每组执行聚合函数(如 sum、avg、count )操作,二者通常结合使用,语法结构如下
<聚合函数>(<表达式>) by (<标签1>, <标签2>, ...)
5.1 分组操作
sum(rate(http_requests_total[5m])) by (job)
5.2 聚合操作
· sum():求和函数,最常用的聚合函数之一,如计算多个CPU总的负载情况
#直接使用聚合函数 sum(increase(node_cpu[1m])) #使用by语句分组 sum(http_requests_total) by (service, environment)
· avg():平均值函数
# 计算平均 CPU 使用率 avg(node_cpu_usage) # 按数据中心计算平均值 avg by (datacenter) (node_cpu_usage)
· max()/min():最大值/最小值
# 查找最高内存使用率 max(node_memory_usage_percentage) # 按服务查找最低响应时间 min by (service) (http_response_time_seconds)
· count()
进行模糊判断,比如有100台服务器在监控,想实现当CPU使用率大于80%的机器达到N台就进行报警就可以使用它
count(count_netstat_wait_connections > 200)
· topk()
取排行前N的数值,比如监控了100台服务器累计320个CPU,用该函数就可以查看当前负载较高的那几个,用于报警
topk(3,count_netstat_wait_connections) #Gauge类型 topk(3,,rate(node_network_receive_bytes[20m])) #Counter类型
· over_time()
over_time类函数有avg_over_time和sum_over_time等,主要区别在于over_time类函数主要用于对单条时间序列上的数据进行聚合,常用于分析单个指标的历史表现
# 计算过去1小时的平均值
avg_over_time(node_cpu_usage[1h])
# 计算多个指标的平均值
avg_over_time(node_memory_usage{instance=~".*"}[1h])
猜你喜欢

运维技术 Prometheus教程(7)使用PushGateway自定义监控
一、PushGateway 介绍在 Prometheus 的体系结构中,需要依赖 PushGateway 来对一些生命周期较短的任务或者无法被 Prometheus 直接拉取到指标的对象进行...
运维技术 Prometheus教程(6)AlertManager告警部署与配置
一、 Alertmanager 介绍AlertManager 是 Prometheus 生态中实现告警管理的关键组件。Prometheus会定期检查指标数据是否与设定好的告警规则匹...
运维技术 Prometheus教程(5)常用exporter的安装与使用配置
一、exporter介绍Prometheus exporter的作用是通过HTTP协议开放符合规范的指标数据给Prometheus抓取。在Prometheus官网提供了大量现成的exporter,基本...

运维技术 Prometheus教程(4)指标类型与常用函数
一、Prometheus 指标类型介绍Prometheus 提供了四种指标类型,这些类型定义了指标值的语义和处理方式,不同的指标类型也有不同的聚合函数搭配使用1、Gauges仪表盘型,该指标类型的值会...
运维技术 Prometheus教程(2)安装部署Grafana并对接Prometheus

一、Grafana介绍Grafana是一款开源的可视化平台,它能够将来自不同数据源的数据(可以集成 Prometheus、Elasticsearch、MySQL 等多种数据源)转换成丰富的图形、图表(...

文章评论