

MySQL教程(5)多表连接查询与子查询
一、MySQL 多表连接查询
多表连接查询是指在多个表中,存在一个或多个相同的字段(这些字段的值必须一致),通过将这些字段连接起来,就能将不同表的数据整合在一起,形成一张包含所有相关信息的大表。这样就可以通过一个查询语句同时获取多个表的数据。多表连接查询按照不同的角度可以分为等值连接和非等值连接、自连接和非自连接以及内连接和外连接。
在多表查询时,最外层的表称为驱动表,该表的查询会先被处理(通常 FROM 中第一个表是驱动表),内层循环的表称为被驱动表,会在驱动表之后进行处理。其工作过程可以看作是一个分步执行的操作,数据库会从第一张表开始,把符合条件的数据逐步“拼接”到最终结果中,整个过程如下:
逐行扫描驱动表:按顺序读取驱动表的每一行。
匹配被驱动表:根据连接条件,在被驱动表中查找所有匹配的行。
拼接结果:将匹配的数据拼接到结果集中。
重复直到完成:对驱动表的每一行重复上述过程,直到所有行都处理完。
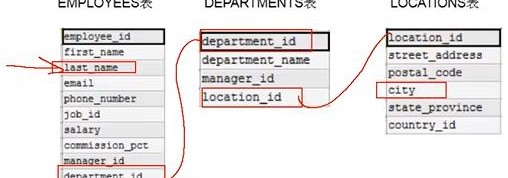
在进行多表连接之前需要确定各个表之间的关系,即它们如何通过共同的列连接在一起,比如外键或者相同字段。以下是一个在不使用多表连接进行员工所在城市的查询过程:
通过EMPLOYEES表查询出了员工姓名和所属部门,这里的关键信息为department_id
通过DEPARTMENTS表查询department_id所在的区域,关键信息为location_id
通过LOCATIONS表的location_id 最终查询出员工所在城市

上面的查询过程使用SQL表示经历了3步,而使用多表连接仅需要一条SQL即可完成整个查询过程
#查询员工tanglu所在城市,在没有多表连接时查询过程如下,会产生多次交互才能获取最终数据 SELECT * FROM employees WHERE last_name = 'tanglu'; #通过员工表找到员工tanglu的department_id(部门id)为80 SELECT * FROM departments department_id = 80 ; #通过department_id=80这个条件在部门表中查询,得到location_id是2500 SELECT * FROM locations WHERE location_id = 2500 ; #通过location_id在地区表中最终找到城市 #使用多表连接时一条语句即可满足上面3条语句的需求 SELECT employee_id,last_name,department_name,city FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.location_id = l.location_id;
1、多表连接关联条件
如果有N个表进行多表查询,那么关联条件至少需要N-1个,以下是一个三表关联查询示例
SELECT employee_id,last_name,department_name,city FROM employees e JOIN departments d #第一个关联 ON e.department_id = d.department_id JOIN locations l #第二个关联 ON d.location_id = l.location_id;
2、MySQL 多表连接语法
在 SQL99 语法里使用JOIN...ON...语句来进行多表连接查询,其中ON用来指定多表之间的连接条件(早期的 SQL92 语法中不需要使用关键词JOIN...ON...,但是MySQL对于SQL92语法支持性不够好,建议使用SQL99语法),在进行多表连接查询时可以先找出需要查询的字段以及所在的表,然后按照固定框架写条件
# SELECT 字段1,字段2,字段3 FROM 表1 # JOIN 表2 ON 关联条件 # JOIN 表3 ON 关联条件
· 内连接(INNER JOIN / JOIN)
内连接是最常用的连接方式,查询结果只返回多表之间匹配上的数据。也就是说只有当两个表中有相同的值时,才会把这些行组合在一起并返回查询结果。假设有员工表(employees)和部门表(departments),employees 表包含字段有 id(员工ID)、name(员工名字)、dept_id(部门ID),departments 表包含字段有 dept_id(部门ID)、dept_name(部门名称)。如果想查询每个员工的姓名和所在的部门名称,可以使用下面语句进行查询,但是只有员工的dept_id和部门的dept_id匹配时,才会返回该行数据,而如果员工没有填写部门信息,将无法查出该名员工
SELECT employees.name, departments.dept_name FROM employees INNER JOIN departments ON employees.dept_id = departments.dept_id;
· 外连接(LEFT JOIN / RIGHT JOIN)
左连接除了返回两表之间相匹配的数据之外,还会返回左表的所有数据,这样就可以解决上面遇到的员工没有填写部门信息而无法查询出来的问题。通常一个查询需求如果是"查询所有xxxxx"这样的描述就要用到外连接。外连接又分左外连接(left join)和右外连接(right join),左外连接是指"两个表在连接过程中除了返回满足条件的行以外,还需要返回左表中的所有行(右外连接则相反)。在实际开发过程中一般都是把数据量多的表放前面,然后使用LEFT JOIN。
SELECT employees.name, departments.dept_name
FROM employees
LEFT JOIN departments ON employees.dept_id = departments.dept_id;

· 自然连接(NATURAL JOIN)
自然连接是一种基于表中相同列名的自动连接方式。SQL 会根据两个表中列名相同的字段自动进行连接,并且不会重复列出相同的列。如果明确两个表有同名的列,并且这些列是用来建立连接的,可以使用 NATURAL JOIN 来自动完成连接,简化代码书写
SELECT employees.name, departments.dept_name
FROM employees
NATURAL JOIN departments;
· USING 连接
由于 NATURAL JOIN 会自动使用所有同名列进行连接,不够灵活。而 USING 提供了更多的灵活性,当多个表中有同名列时,可以用 USING 来明确指定作为连接条件的列
SELECT employees.name, departments.dept_name
FROM employees
JOIN departments USING (dept_id);
· 自连接多表查询
自连接查询是指将同一张表进行关联,在逻辑上这一张表等同于两张表,所以在查询的时候用自己和自己做关联即可
#通过员工信息表进行自连接查询,查出每个员工以及他的上级姓名,这里用到的连接条件就是员工表manager_id与管理者表employee_id相关联(虽然这里分为了员工表和管理者表,但实际就是一张表)
SELECT e.employee_id,e.first_name,m.first_name AS manager FROM employees e JON employees m ON e.manager_id = m,employee_id
· 复合连接查询
当存在无法用单一列准确标识某张表里的情况时,就需要组合不同的列来构成唯一行,这种就叫复合连接查询
SELECT * FROM order_items oi
JOIN order_item_notes oin
ON oi.order_id = oin.order_id
AND oi.product_id = oin.product_id
3、MySQL 多表连接性能问题
多表连接的本质是对多表之间数据进行循环匹配,首先扫描驱动表获取到数据,然后用这些数据再和另外一张表进行比较匹配。在比较匹配算法上,MySQL支持INLJ、BNLJ、SNLJ 3种(从8.0.20开始废弃BNLJ,由HASH JOIN替代),在整体效率上INLJ >BNLJ>SNLJ。SNLJ就是把驱动表中符合条件的数据一条一条拿到被驱动表中进行匹配(笛卡尔积),而BNLJ则是把驱动表中的多条数据放到JOIN BUFFER中一起进行匹配,性能更高。
· 控制关联表数量
由于JOIN查询方式非常消耗资源,所以要控制关联表的数量,尽量不要超过3张表
· 小表驱动大表
因为外层循环决定了整个扫描的次数,所以用小表驱动大表可以有效减少循环次数,并且要为被驱动表的匹配条件增加索引,减少内层表循环的匹配次数。假设有users表(100行数据)和orders(10000条数据)两个表,它们通过id进行关联查询,如果 users表作为驱动表,数据库会先从 users 表中取一行,然后到 orders 表中匹配所有相关数据,这样相当于进行了外层100次扫描和内层100次扫描。而如果 orders 是驱动表,数据库会先从 orders 表中取一行,再到 users 表中匹配数据。此时外层循环高达 10000 次,且内层也需要循环扫描10000 次。
举个生活中的例子。假设老师核对学生出勤情况,此时有出勤名单记录了当天的学生出勤情况(小表,10人),全校学生名单记录了全校学生的详细信息(大表,1000人)。如果想找出出勤学生的详细信息,最合理的方式是先从 出勤名单 里挑出 10 个学生的名字,然后在 全校学生名单 中匹配这 10 个名字,这样只需要匹配 10 次即可。但如果反过来从 全校学生名单 中逐行检查每个学生是否出现在出勤名单中,会导致 1000 次匹配操作,效率明显更低。
SELECT users.name, orders.order_id, orders.amount FROM users JOIN orders ON users.user_id = orders.user_id;
· 多表连接笛卡尔乘积问题
在使用多表连接查询的时候,需要注意笛卡尔积问题,如果使用了错误的查询方式、缺少连接条件的话,就会出现交叉连接,也叫做笛卡尔积(笛卡尔积是一个数学运算,假设有两个集合X和Y,X和Y的笛卡尔积就是X和Y的所有可能的组合),会把每个员工与每个部门进行匹配,这样会产生大量的冗余查询。为了避免笛卡尔积的错误出现,需要在WHERE子句后添加正确的连接条件,也就是说可以让两张表中形成组合关系的字段
SELECT employee_id,department_name FROM employees,departments #错误的查询方式 SELECT employee_id,department_name FROM employess JOIN departments ON employees.department_id = departments.department_id
如果查询语句中出现了多个表共有的字段,则必须指明字段所在的表。从SQL优化的角度,建议多表查询时,每个字段前都声明所属表名
#指明department_id字段所属表 SELECT employee_id,department_name,employees.department_id FROM employess JOIN departments ON employees.department_id = departments.department_id
二、MySQL子查询介绍
使用子查询可以实现SELECT语句的嵌套查询,即一个SELECT的查询结果作为另一个SELECT的查询条件。子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作,比如要查询企业中哪些员工的工资比张三高,那就需要先查询张三的工资。
在整个查询语句结构中,最外层的查询称为主查询,其余嵌套查询都作为它的子查询语句。虽然子查询是一项重要的功能,但是它的查询性能并不高,因为执行子查询时会将内层语句的查询结果存放在内存临时表中,主查询再通过临时表进行查询,最后删除这个临时表,这些过程都会导致CPU和IO资源的消耗。并且子查询结果集存放的临时表不会存在索引,查询性能会再一次受到影响。所以在进行复杂查询时可以考虑尽量用多表连接代替子查询。
1、子查询的相关特性
· 子查询主要解决AVG等聚合函数不能写在WHERE条件中的问题
· 通常要对聚合函数进行嵌套的话就可以考虑使用子查询(Oracle中聚合函数可以嵌套,如min(avg())
· 单行子查询:子查询的查询结果只有1条数据,对于单行子查询可以使用的操作符有=、!=、>、<、>=、<=
· 多行子查询:子查询的查询结果大于1条数据,对于多行子查询可以使用的操作符有IN(等于列表中的任意一个)、ANY(需要和单行操作符一起使用,和子查询返回的其中一个值进行比较)、ALL(需要和单行操作符一起使用,和子查询返回的其中所有值进行比较)。如果主查询中使用了像=、!=这样的关联条件就会返回subquery return more than 1row的错误
· 相关子查询:如果子查询中的数据是动态变化的,一般为相关子查询。比如需要查询工资大于部门平均工资的员工,这个时候内层查询的数据会随着主查询中员工信息发生变化,比如A员工对于SALES部门、B员工对应IT部门
· 如果子查询并没有返回数据,那么整个查询结果为空而不报错
2、MySQL子查询示例
查询工资大于149号员工的其他员工信息
SELECT employee_id,last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE employee_id = 149 ); #查询工资大于张三的员工 SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name='zhangsan');
查询工号与141号员工相同、工资比143号员工多的其他员工的姓名、job_id和工资
SELECT last_name,job_id,salary FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 ) AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 )
查询最低工资大于110号部门中最低工资的部门ID和该部门最低工资(在HAVING中使用子查询)
SELECT department_id,MIN(salary) FROM employees WHERE department_id IS NOT NULL GROUP BY department_id HAVING MIN(salary) > ( SELECT MIN(salary) FROM employees WHERE department_id = 110 )
查询结果显示employee_id,last_name和location三个字段,其中location字段的值需要进行判断,如果员工department_id和location_id为1800的department_id相同则location显示CANADA,否则显示USA(在CASE中使用子查询)
SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id=1800) ELSE 'USA' END "location" FROM employees;
查询除IT部门外其他所有部门中工资比IT部门所有人都要低的员工信息(多行子查询)
SELECT employee_id,last_name,job_ib,salary FROM employees WHERE job_id <> 'IT' AND salary < ALL ( SELECT salary FROM employees WHERE job_id = 'IT' )
查询平均工资最低的部门ID(把子查询的结果作为一张表,解决聚合函数嵌套问题)
SELECT MIN(avg_salary) FROM ( SELECT AVG(salary) avg_salary FROM employees GROUP BY department_id ) t_dept_avg_salary #必须为子查询起一个表别名


猜你喜欢
MySQL | Oracle 【MySQL 8.0】MySQL 8.0新特性介绍与升级方法
一、MySQL 8.0主要新特性截至2023年12月,MySQL官方发布的稳定版为8.0.35,另有一个MySQL8.2为创新版,所以暂不做考虑· 快速新增/删除列虽然 MySQL 在8.0 以前就已...

MySQL | Oracle 【MySQL 8.0】MySQL5.7升级MySQL8.0的步骤与常见问题
一、为什么推荐将MySQL从5.7升级到8.0MySQL5.7的生命周期已经在2023年10月结束,沿用老版本将存在以下问题:· 所有漏洞不再修复,如自增ID回退问题· 核心新特性无法使用,...
MySQL | Oracle Oracle教程(4)快照与AWR报告
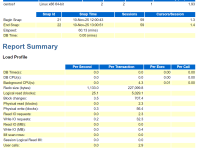
一、Oracle 快照Oracle中的快照(Snapshot)是指数据库在某个时间点对性能相关的数据做的一次全量采集。包括:系统资源使用情况、Top SQL、IO 性能指标、SGA、PGA 使用情况。...

MySQL | Oracle Oracle教程(3)Schema、用户与表空间
在完成 Oracle安装后,登录数据库实例可以看到有很多的模式(Schema),这些模式都是为了支持数据库核心组件、特性扩展、管理任务或者示例而创建,对于这部分默认模式,通常不需要进行操作。在生产规范...

MySQL | Oracle Oracle教程(2)Oracle19C命令行静默安装教程
在部分生产环境下可能并不支持通过图形化方式来安装Oracle数据库(比如需要脚本一键安装的场景),所以还需要了解通过命令行静默安装的方式来完整数据库的安装,以下是详细步骤一、系统环境配置部分1、确定内...

文章评论